Gaussian is very important distribution. During this post, we will discuss the detail of Gaussian distribution by deriving it, calculate the integral value and do MLE (Maximum Likelihood Estimation). To derive Gaussian distribution, it is more difficult if we do it in cartesian coordinate. Thus, we will use polar coordinate. Before we derive the Gaussian using polar coordinate, let’s talk about how to change the coordinate system from cartesian to polar coordinate system first.
(1) Changing coordinate system from cartesian to polar coordinate
Changing coordinate system from catersian to polar coordinate is useful, such as when we calculate integral of certain function, in certain case, we prefer to use polar coordinate system because it will be away easier to calculate. To do that, we can use Jacobian matrix. Jacobian matrix actually defines partial derivative of a vector with respect to another vector. In our case changing cartesian coordinate to polar coordinate, the Jacobian matrix of 


Then, changing coordinate system from cartesian coordinate to polar coordinate, it can be done by this formula.


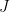
Let’s do an example! See picture below.

To calculate the circle area, we can do as follows.



We can calculate the circle area by using coordinate polar resulting exactly same with what we get above. See picture below.

In cartesian coordinate, we calculate by dividing the circle area into small box 



with

and

Let’s proceed our calculation.
Deriving Gaussian Distribution

See the result. We successfully calculate the circle area using polar coordinate easily where the final result is same with circle area formula we are familiar about.
(2) Deriving Gaussian distribution using polar coordinate
Let’s put the condition first. We already know that the Gaussian distribution, closer to the original point (would be in 0,0 for zero mean case), bigger its value is. In two dimensions, the distribution is shown picture below.
 Another characteristic we know is that the distribution is symmetric both in axis x and y. Using these assumptions, we will try to derive what is the mathematical formula of it. Again, we will use polar coordinate to make the derivation process easier. See picture below.
Another characteristic we know is that the distribution is symmetric both in axis x and y. Using these assumptions, we will try to derive what is the mathematical formula of it. Again, we will use polar coordinate to make the derivation process easier. See picture below.

This is Gaussian distribution if we see from the top, and we put polar coordinate 




![\frac{d[g(r)]}{d\theta}=\frac{d[P(x)P(y)]}{d\theta}](https://s0.wp.com/latex.php?latex=%5Cfrac%7Bd%5Bg%28r%29%5D%7D%7Bd%5Ctheta%7D%3D%5Cfrac%7Bd%5BP%28x%29P%28y%29%5D%7D%7Bd%5Ctheta%7D&bg=ffffff&fg=000000&s=0&c=20201002)
We know that in Gaussian distribution, 

![0=P(x)\frac{d[P(y)]}{d\theta}+P(y)\frac{d[P(x)]}{d\theta}](https://s0.wp.com/latex.php?latex=0%3DP%28x%29%5Cfrac%7Bd%5BP%28y%29%5D%7D%7Bd%5Ctheta%7D%2BP%28y%29%5Cfrac%7Bd%5BP%28x%29%5D%7D%7Bd%5Ctheta%7D&bg=ffffff&fg=000000&s=0&c=20201002)
By substituting 


By substituting back 


In Gaussian distribution, this differential equation is true for any

Solving 

Since this is probability distribution function, thus, it sums to 1.

Let 

Because the distribution is symmetric, and 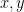

Let’s solve two those integrals using coordinate polar like we already did before.

For integral w.r.t 

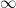

Let 

The last, to find 




Next, we will solve equation above using integral by part (

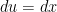


Let 

Thus,

Let’s back to solve our integral by part.

We know from what we already get before that 

Hooray! We already successfully calculate all we need in deriving Gaussian distribution. The last, we just plug 
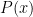

Equation above is for mean 


Up to this point, we already successfully derive Gaussian distribution function. Congratulation!
(3) Integralling Gaussian function using polar coordinate
We will integralling simple Gaussian function 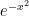


Let 


We’ve made it! We just successfully derived given Gaussian distribution.
(4) Maximum Likelihood Estimation of Gaussian distribution
Like we already did before in Bernoulli and Beta distribution here, we will also do MLE in this Gaussian distribution discussion. We will try to estimate mean (
Let say we have trial result 
The likelihood of Gaussian distribution is defined below.

To maximize this, as usual, we will take first differential and make it equal to zero. But, before it, to make it easier, let’s do in 
![\underset{\theta}{argmax}[lnP(D|\theta)]=\sum_{i=1}^{n}ln(\frac{1}{\sqrt{2\pi}\sigma}e^{\frac{-(x_i-\mu)^2}{2\sigma^2}})\\\\ \underset{\theta}{argmax}[lnP(D|\theta)]=\sum_{i=1}^{n}ln(\frac{1}{\sqrt{2\pi}\sigma})+\sum_{i=1}^{n}log(e^{\frac{-(x_i-\mu)^2}{2\sigma^2}})\\\\ \underset{\theta}{argmax}[lnP(D|\theta)]=n\,ln(\frac{1}{\sqrt{2\pi}\sigma})+\sum_{i=1}^{n}\frac{-(x_i-\mu)^2}{2\sigma^2}ln(e)\\\\ \underset{\theta}{argmax}[lnP(D|\theta)]=n\,ln(2\pi\sigma^2)^{-\frac{1}{2}}-\sum_{i=1}^{n}\frac{(x_i-\mu)^2}{2\sigma^2}\\\\ \underset{\theta}{argmax}[lnP(D|\theta)]=-\frac{n}{2}\,ln(2\pi\sigma^2)-\sum_{i=1}^{n}\frac{(x_i-\mu)^2}{2\sigma^2}](https://s0.wp.com/latex.php?latex=%5Cunderset%7B%5Ctheta%7D%7Bargmax%7D%5BlnP%28D%7C%5Ctheta%29%5D%3D%5Csum_%7Bi%3D1%7D%5E%7Bn%7Dln%28%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Cpi%7D%5Csigma%7De%5E%7B%5Cfrac%7B-%28x_i-%5Cmu%29%5E2%7D%7B2%5Csigma%5E2%7D%7D%29%5C%5C%5C%5C++%5Cunderset%7B%5Ctheta%7D%7Bargmax%7D%5BlnP%28D%7C%5Ctheta%29%5D%3D%5Csum_%7Bi%3D1%7D%5E%7Bn%7Dln%28%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Cpi%7D%5Csigma%7D%29%2B%5Csum_%7Bi%3D1%7D%5E%7Bn%7Dlog%28e%5E%7B%5Cfrac%7B-%28x_i-%5Cmu%29%5E2%7D%7B2%5Csigma%5E2%7D%7D%29%5C%5C%5C%5C++%5Cunderset%7B%5Ctheta%7D%7Bargmax%7D%5BlnP%28D%7C%5Ctheta%29%5D%3Dn%5C%2Cln%28%5Cfrac%7B1%7D%7B%5Csqrt%7B2%5Cpi%7D%5Csigma%7D%29%2B%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5Cfrac%7B-%28x_i-%5Cmu%29%5E2%7D%7B2%5Csigma%5E2%7Dln%28e%29%5C%5C%5C%5C++%5Cunderset%7B%5Ctheta%7D%7Bargmax%7D%5BlnP%28D%7C%5Ctheta%29%5D%3Dn%5C%2Cln%282%5Cpi%5Csigma%5E2%29%5E%7B-%5Cfrac%7B1%7D%7B2%7D%7D-%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5Cfrac%7B%28x_i-%5Cmu%29%5E2%7D%7B2%5Csigma%5E2%7D%5C%5C%5C%5C++%5Cunderset%7B%5Ctheta%7D%7Bargmax%7D%5BlnP%28D%7C%5Ctheta%29%5D%3D-%5Cfrac%7Bn%7D%7B2%7D%5C%2Cln%282%5Cpi%5Csigma%5E2%29-%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5Cfrac%7B%28x_i-%5Cmu%29%5E2%7D%7B2%5Csigma%5E2%7D&bg=ffffff&fg=000000&s=0&c=20201002)
First, let’s derive
![\mu_{_{MLE}} \rightarrow \frac{\delta [log\, likelihood]}{\delta \mu}=\frac{\delta[-\frac{n}{2}\,ln(2\pi\sigma^2)]}{\delta \mu}-\frac{\delta[\sum_{i=1}^{n}\frac{(x_i-\mu)^2}{2\sigma^2}]}{\delta \mu}=0\\\\ 0-\frac{1}{2\sigma^2}\frac{\delta[\sum_{i=1}^{n}(x_i^2-2x_i\mu+\mu^2)]}{\delta \mu}=0\\\\ \sum_{i=1}^{n}(2\mu-2x_i)=0\\\\ \boxed{\mu_{_{MLE}}=\frac{\sum_{i=1}^{n}x_i}{n}}](https://s0.wp.com/latex.php?latex=%5Cmu_%7B_%7BMLE%7D%7D+%5Crightarrow+%5Cfrac%7B%5Cdelta+%5Blog%5C%2C+likelihood%5D%7D%7B%5Cdelta+%5Cmu%7D%3D%5Cfrac%7B%5Cdelta%5B-%5Cfrac%7Bn%7D%7B2%7D%5C%2Cln%282%5Cpi%5Csigma%5E2%29%5D%7D%7B%5Cdelta+%5Cmu%7D-%5Cfrac%7B%5Cdelta%5B%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5Cfrac%7B%28x_i-%5Cmu%29%5E2%7D%7B2%5Csigma%5E2%7D%5D%7D%7B%5Cdelta+%5Cmu%7D%3D0%5C%5C%5C%5C++0-%5Cfrac%7B1%7D%7B2%5Csigma%5E2%7D%5Cfrac%7B%5Cdelta%5B%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28x_i%5E2-2x_i%5Cmu%2B%5Cmu%5E2%29%5D%7D%7B%5Cdelta+%5Cmu%7D%3D0%5C%5C%5C%5C++%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%282%5Cmu-2x_i%29%3D0%5C%5C%5C%5C++%5Cboxed%7B%5Cmu_%7B_%7BMLE%7D%7D%3D%5Cfrac%7B%5Csum_%7Bi%3D1%7D%5E%7Bn%7Dx_i%7D%7Bn%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
See. Equation above is exactly same with what we already know about calculating mean value. Next, we will try to calculate variance. To do this, we take the first differential w.r.t
![\sigma^2_{_{MLE}} \rightarrow \frac{\delta log [likelihood]}{\delta \sigma^2}=\frac{\delta[-\frac{n}{2}\,ln(2\pi\sigma^2)]}{\delta \sigma^2}-\frac{\delta[\sum_{i=1}^{n}\frac{(x_i-\mu)^2}{2\sigma^2}]}{\delta \sigma^2}=0\\\\ \frac{\delta[-\frac{n}{2}\,ln(2\pi)]}{\delta \sigma^2}+\frac{\delta[-\frac{n}{2}\,ln(\sigma^2)]}{\delta \sigma^2}-\frac{\delta[(\sigma^2)^{-1}\sum_{i=1}^{n}\frac{(x_i-\mu)^2}{2}]}{\delta \sigma^2}=0\\\\ 0+-(\sigma^2)^{-1}\frac{n}{2}\,ln(e)+(\sigma^2)^{-2}\sum_{i=1}^{n}\frac{(x_i-\mu)^2}{2}=0](https://s0.wp.com/latex.php?latex=%5Csigma%5E2_%7B_%7BMLE%7D%7D+%5Crightarrow+%5Cfrac%7B%5Cdelta+log+%5Blikelihood%5D%7D%7B%5Cdelta+%5Csigma%5E2%7D%3D%5Cfrac%7B%5Cdelta%5B-%5Cfrac%7Bn%7D%7B2%7D%5C%2Cln%282%5Cpi%5Csigma%5E2%29%5D%7D%7B%5Cdelta+%5Csigma%5E2%7D-%5Cfrac%7B%5Cdelta%5B%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5Cfrac%7B%28x_i-%5Cmu%29%5E2%7D%7B2%5Csigma%5E2%7D%5D%7D%7B%5Cdelta+%5Csigma%5E2%7D%3D0%5C%5C%5C%5C++%5Cfrac%7B%5Cdelta%5B-%5Cfrac%7Bn%7D%7B2%7D%5C%2Cln%282%5Cpi%29%5D%7D%7B%5Cdelta+%5Csigma%5E2%7D%2B%5Cfrac%7B%5Cdelta%5B-%5Cfrac%7Bn%7D%7B2%7D%5C%2Cln%28%5Csigma%5E2%29%5D%7D%7B%5Cdelta+%5Csigma%5E2%7D-%5Cfrac%7B%5Cdelta%5B%28%5Csigma%5E2%29%5E%7B-1%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5Cfrac%7B%28x_i-%5Cmu%29%5E2%7D%7B2%7D%5D%7D%7B%5Cdelta+%5Csigma%5E2%7D%3D0%5C%5C%5C%5C++0%2B-%28%5Csigma%5E2%29%5E%7B-1%7D%5Cfrac%7Bn%7D%7B2%7D%5C%2Cln%28e%29%2B%28%5Csigma%5E2%29%5E%7B-2%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5Cfrac%7B%28x_i-%5Cmu%29%5E2%7D%7B2%7D%3D0&bg=ffffff&fg=000000&s=0&c=20201002)
Multiplying both side with 

Variance formula we get via MLE is also exactly same with the variance formula what we already know about. Up to this point, we already know that given trials data experiment, we can fit the probability distribution into Gaussian distribution by parameter

how to make honey oil for vape pen