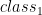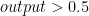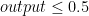In this machine learning and pattern recognition series, we already talk about regression problem that the output prediction is in continuous value. In machine learning, predicting output in discrete value given input is called classification. For two possible outputs, we usually call it as binary classification. For example, predicting that certain bank transaction is fraud or not, predicting that the cancer is benign or malignant, predicting that tomorrow will be raining or not, and so on. Whereas, for more than two possible outputs, we call it multi-class classification. For example, classification in hand gesture recognition whether the hand is moving right, left, bottom or up, classifying digit number 0 to 9, and so on.
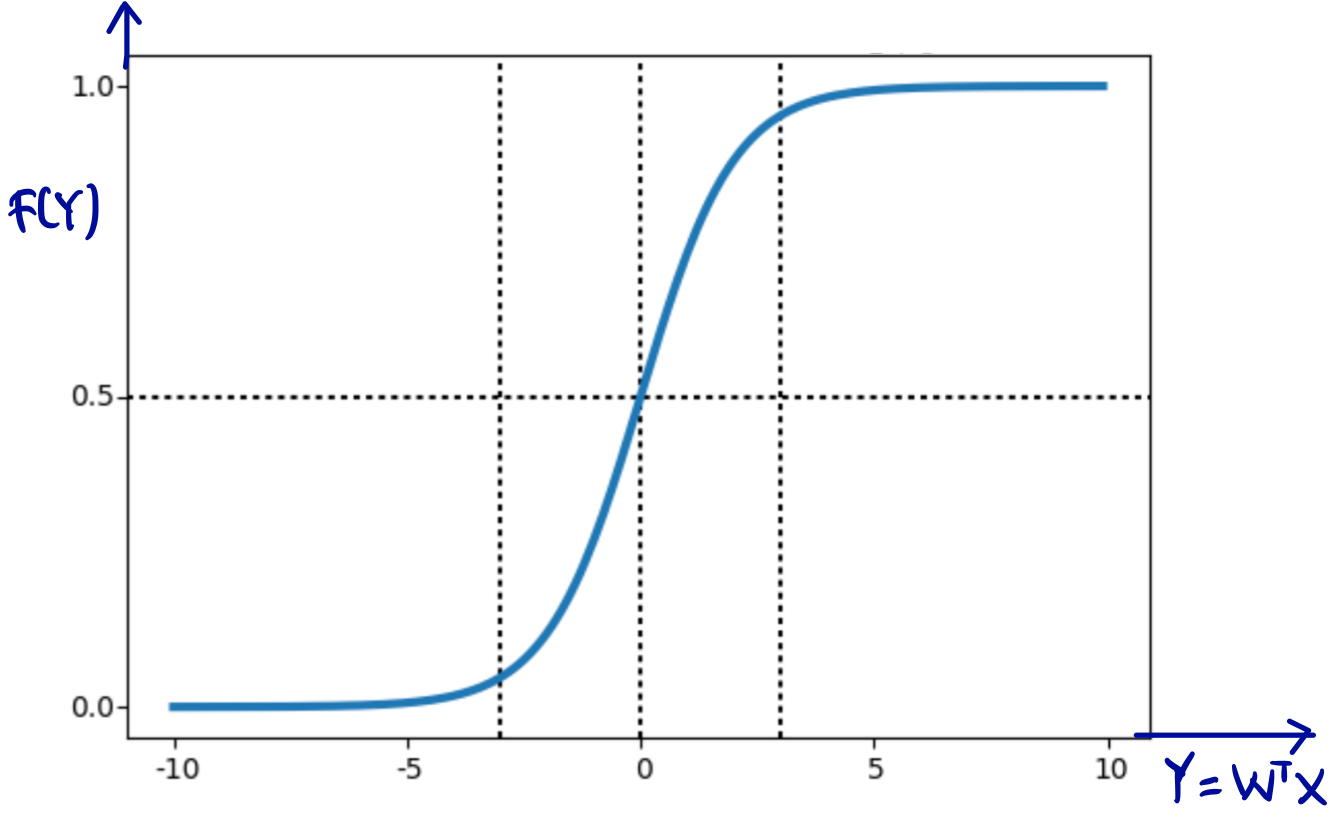
Even thought classification is similar with regression, and the difference is only that classification output is discrete, whereas regression output is continuous, we can’t use exactly same method of regression for classification. The reason are : (1) it will perform bad when we classify given input to many classes, and (2) it lacks robustness to outliers. To use regression approach for classification, we need so-called activation function. Such method is called logistic regression, and we will talk later here. It is called logistic “regression” because we use similar way with what we did in regression here, but instead of taking output  as prediction output, we feed the output into logistic function. The logistic function that is often used is sigmoid function. Furthermore, even its name uses “regression”, it is for classification problem, not regression problem. Continue reading “Introduction to Classification and Confusion Matrix” →
as prediction output, we feed the output into logistic function. The logistic function that is often used is sigmoid function. Furthermore, even its name uses “regression”, it is for classification problem, not regression problem. Continue reading “Introduction to Classification and Confusion Matrix” →