We already derive the posterior update formula 


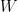


From #Part1 here, we already get 

where 

.Tempat berbagi catatan. Indonesian.
We already derive the posterior update formula
From #Part1 here, we already get
where
In the beginning of our article series, we already talk about how to derive polynomial regression using LSE (Linear Square Estimation) here. During this post, we will try to discuss linear regression from Bayesian point of view. Note that linear and polynomial regression here are similar in derivation, the difference is only in design matrix. You may check again our couple previous articles here and here.
I let you know in the beginning that the final result of deriving regression using LSE is equal to the result of deriving linear regression using MLE (Maximal Likelihood Estimation) in Bayesian method. Furthermore, the result of deriving regression using LSE with regularization is equal to the result of deriving using MAP (Maximum A Posteriori) in Bayesian method. During this post, we will try to prove it. And we will proceed to derive the posterior update formula for online learning using Conjugate prior.
See picture below.

We already discuss how online learning works here using Conjugate distributions with Binomial distribution as the likelihood and Beta distribution as conjugate prior distribution. During this post, we will try to use Gaussian distribution for online learning in Bayesian inference. Conjugate prior of Gaussian distribution is Gaussian itself. That’s why we call Gaussian distribution self-conjugate. Let’s try to derive it.
Given trial result 
We will try to derive the posterior 







After we understand the concept of Bernoulli, Binomial and Beta distribution we discuss here, we are ready to understand online learning used in Bayesian inference now. In Bayesian theorem we discuss here, we have equation below.
And for multi classes 

Using rule of sum with 


Here, we can say 



In online learning, we will update our prior probability when we do some new trials. For example, in the first stage, we do some tossing coin, and we model the prior probability with 




