Hallo teman-teman semuanya!
Di post ini, saya akan membagikan video series yang akan membahas materi image processing dan computer vision. Video series ini akan membahas detail teorinya, kemudian di sesi berikutnya diikuti dengan praktek implementasi di pemrograman C++ menggunakan libary OpenCV.
Materi diadopsi dari bukunya Gonzales “Digital Image Processing” dari Chapter 1 hingga Chapter 12, yaitu Object Detection, ditambah dengan beberapa topik computer vision, seperti stereo vision. Adapun slide dan code-nya tersedia di link Github di sini. Slide dan code tersebut dapat digunakan secara gratis, baik untuk referensi perkuliahan hingga untuk self-study, dengan tetap mencantumkan sumbernya.
Semoga video series ini membantu teman-teman dalam memahami image processing dan computer vision, dan ikut membantu tumbuhnya iklim science & engineering di Indonesia. Salam 🙂
Continue reading “Image Processing & Computer Vision Video Series”
![J(\textbf{a})=\frac{1}{2m}[(\textbf{Xa}-\boldsymbol{y})^2+\lambda \textbf{a}^T\textbf{a}]\\\\ J(\textbf{a})=\frac{1}{2m}[(\textbf{Xa})^T\textbf{Xa}-2\textbf{Xa}^T\textbf{y}+\textbf{y}^T\textbf{y}+\lambda \textbf{a}^T\textbf{a}]](https://s0.wp.com/latex.php?latex=J%28%5Ctextbf%7Ba%7D%29%3D%5Cfrac%7B1%7D%7B2m%7D%5B%28%5Ctextbf%7BXa%7D-%5Cboldsymbol%7By%7D%29%5E2%2B%5Clambda+%5Ctextbf%7Ba%7D%5ET%5Ctextbf%7Ba%7D%5D%5C%5C%5C%5C++J%28%5Ctextbf%7Ba%7D%29%3D%5Cfrac%7B1%7D%7B2m%7D%5B%28%5Ctextbf%7BXa%7D%29%5ET%5Ctextbf%7BXa%7D-2%5Ctextbf%7BXa%7D%5ET%5Ctextbf%7By%7D%2B%5Ctextbf%7By%7D%5ET%5Ctextbf%7By%7D%2B%5Clambda+%5Ctextbf%7Ba%7D%5ET%5Ctextbf%7Ba%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 is parameter we want to estimate/observe, our estimator result will be
is parameter we want to estimate/observe, our estimator result will be  . The bias of our estimator is defined as follows.
. The bias of our estimator is defined as follows.![bias = E[\hat{\theta}]-\theta](https://s0.wp.com/latex.php?latex=bias+%3D+E%5B%5Chat%7B%5Ctheta%7D%5D-%5Ctheta&bg=ffffff&fg=000000&s=0&c=20201002)

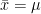 and
and 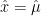
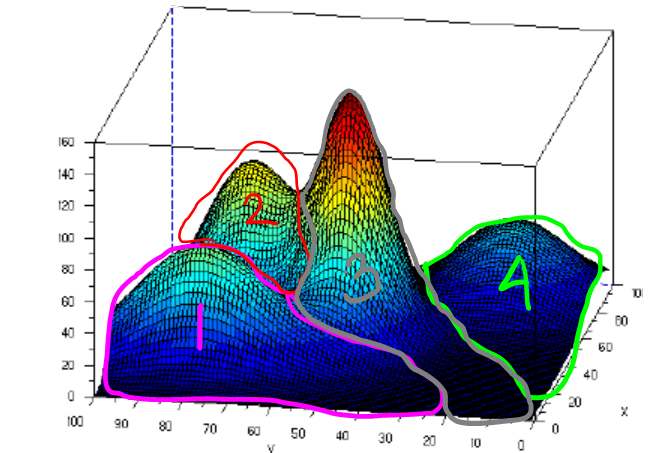
 into so-called activation function, usually using sigmoid acivation function. See piture below.
into so-called activation function, usually using sigmoid acivation function. See piture below.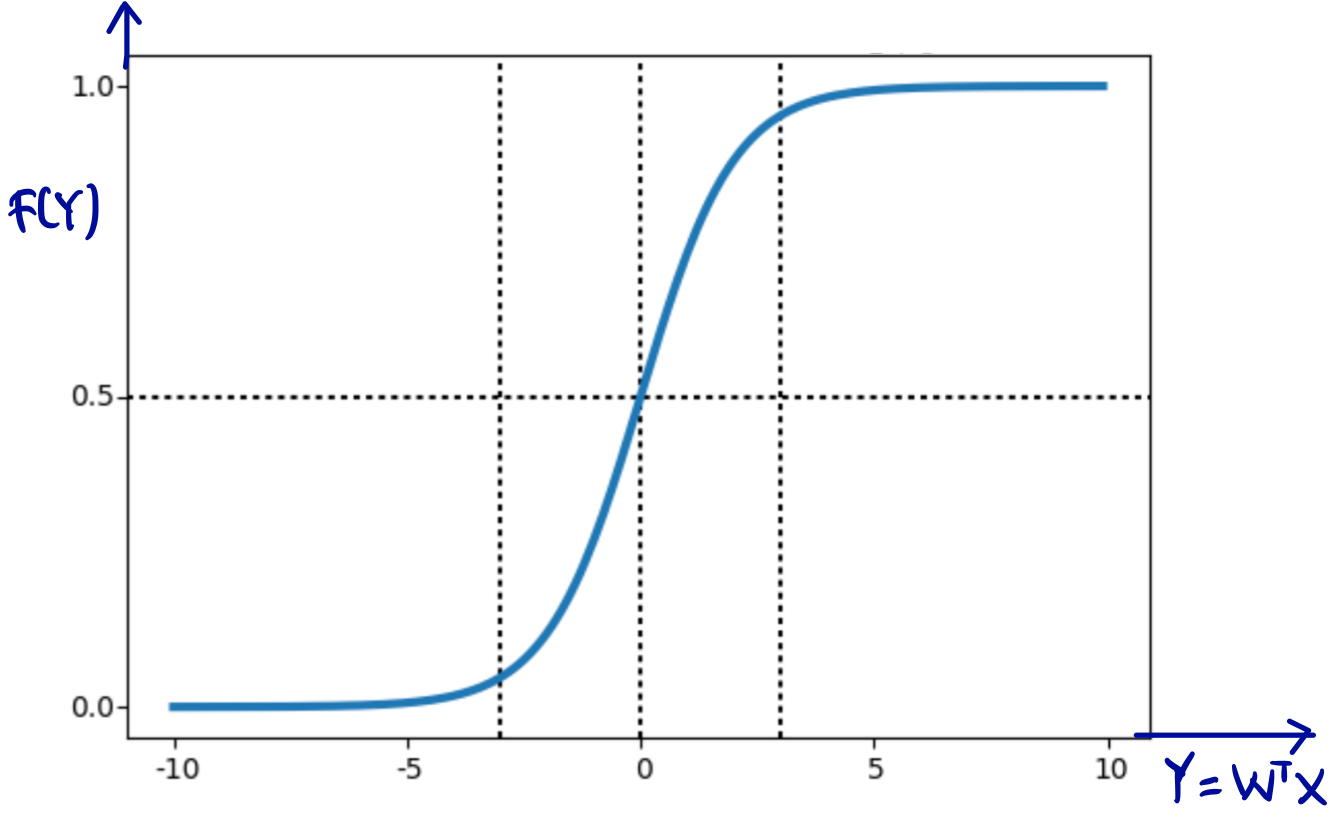
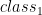 when the output is closed to 1 (formally when
when the output is closed to 1 (formally when 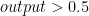 ) and classify to $class_2$ when the output is closed to 0 (formally when
) and classify to $class_2$ when the output is closed to 0 (formally when 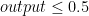 ) To do that, we can achieve by maximizing out likelihood using MLE (Maximum Likelihood Estiamtion).
) To do that, we can achieve by maximizing out likelihood using MLE (Maximum Likelihood Estiamtion).