We already derive the posterior update formula  for Bayesian regression here, telling us that it is distribution of our parameter regression
for Bayesian regression here, telling us that it is distribution of our parameter regression  given data set
given data set  . We are not directly interested in the value of
. We are not directly interested in the value of 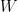 , but, we are interested in the value of
, but, we are interested in the value of  itself given new value of new
itself given new value of new  . This is exactly same with regression problem, given new value , we want to predict output value of , which is in continuous value mode. And we already did linear regression problem using LSE (Least Square Error) here. During this post, we will do regression from Bayesian point of view. Using Bayesian in regression, we will have additional benefit. We will see later in the end of this post.
. This is exactly same with regression problem, given new value , we want to predict output value of , which is in continuous value mode. And we already did linear regression problem using LSE (Least Square Error) here. During this post, we will do regression from Bayesian point of view. Using Bayesian in regression, we will have additional benefit. We will see later in the end of this post.
From #Part1 here, we already get . To do regression in Bayesian point of view, we have to derive predictive distribution, so that we will have probability of ,  . We can achieve that by doing marginalization. Here we go.
. We can achieve that by doing marginalization. Here we go.

where  is likelihood and
is likelihood and  is posterior we derive here Continue reading “Bayesian Linear / Polynomial Regression #Part2: Deriving Predictive Distribution” →
is posterior we derive here Continue reading “Bayesian Linear / Polynomial Regression #Part2: Deriving Predictive Distribution” →
