We already derive the posterior update formula 


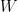


From #Part1 here, we already get 

where 

.Tempat berbagi catatan. Indonesian.
We already derive the posterior update formula
From #Part1 here, we already get
where
We already discuss Gaussian distribution function with one variable (univariate) here. In this post, we will discuss about Gaussian distribution function with multi variables (multivariate), which is the general form of Gaussian distribution. For 
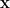
where 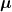
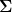
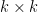

We already discuss how online learning works here using Conjugate distributions with Binomial distribution as the likelihood and Beta distribution as conjugate prior distribution. During this post, we will try to use Gaussian distribution for online learning in Bayesian inference. Conjugate prior of Gaussian distribution is Gaussian itself. That’s why we call Gaussian distribution self-conjugate. Let’s try to derive it.
Given trial result 
We will try to derive the posterior 







Gaussian is very important distribution. During this post, we will discuss the detail of Gaussian distribution by deriving it, calculate the integral value and do MLE (Maximum Likelihood Estimation). To derive Gaussian distribution, it is more difficult if we do it in cartesian coordinate. Thus, we will use polar coordinate. Before we derive the Gaussian using polar coordinate, let’s talk about how to change the coordinate system from cartesian to polar coordinate system first.
Changing coordinate system from catersian to polar coordinate is useful, such as when we calculate integral of certain function, in certain case, we prefer to use polar coordinate system because it will be away easier to calculate. To do that, we can use Jacobian matrix. Jacobian matrix actually defines partial derivative of a vector with respect to another vector. In our case changing cartesian coordinate to polar coordinate, the Jacobian matrix of 





