After we discuss about polynomial regression here using LSE (Least Square Error), we know that higher order of polynomial model has more capability to fit more complex data points, but more prone to be overfitting. Picture below illustrates that red line (using high order) exactly fit those blue dot points, but will give big error, such as in axis 0.9. That is what we called overfitting (away too fit data training). In this case, green line is better, that has more general model to represent those data points.

We can avoid overfitting by using so-called regularization. How does it work? Usually, a function is prone to be overfitting when its coefficients (weighting values) has big value and not well distributed. Thus, we will force our training process to make those coefficients small by adding a term in our cost function. This process also makes those coefficients more well distributed. Here is our new cost function.
![J(\mathbf{a})=\frac{1}{2m}[\sum_{i=1}^{m}(h(x_i)-y_i)^2)+\lambda\sum_{j=1}^{n}a_j^2]](https://s0.wp.com/latex.php?latex=J%28%5Cmathbf%7Ba%7D%29%3D%5Cfrac%7B1%7D%7B2m%7D%5B%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%28h%28x_i%29-y_i%29%5E2%29%2B%5Clambda%5Csum_%7Bj%3D1%7D%5E%7Bn%7Da_j%5E2%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
with our hypothesis funtion
There are two terms in equation above. Since we will minimize 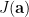


We will do some linear algebra to simplify our cost function. For first term, we already derive here giving us 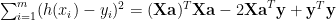

Re-writing for 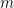


Thus, our cost function 
![J(\mathbf{a})=\frac{1}{2m}[(\mathbf{Xa})^T\mathbf{Xa}-2\mathbf{Xa}^T\mathbf{y}+\mathbf{y}^T\mathbf{y}+(\lambda n \mathbf{I} \mathbf{a})^T\mathbf{a}]](https://s0.wp.com/latex.php?latex=J%28%5Cmathbf%7Ba%7D%29%3D%5Cfrac%7B1%7D%7B2m%7D%5B%28%5Cmathbf%7BXa%7D%29%5ET%5Cmathbf%7BXa%7D-2%5Cmathbf%7BXa%7D%5ET%5Cmathbf%7By%7D%2B%5Cmathbf%7By%7D%5ET%5Cmathbf%7By%7D%2B%28%5Clambda+n+%5Cmathbf%7BI%7D+%5Cmathbf%7Ba%7D%29%5ET%5Cmathbf%7Ba%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Again, our purpose is to minimize our cost function. In this case, we will find parameter 
![J(\mathbf{a})=\frac{1}{2m}[(\mathbf{Xa})^T\mathbf{Xa}-2(\mathbf{Xa})^T\mathbf{y}+\mathbf{y}^T\mathbf{y}+\lambda n \mathbf{I} \mathbf{a}^T\mathbf{a}] \\\\ \frac{dJ(\mathbf{a})}{d\mathbf{a}}=\frac{1}{2m}[2\mathbf{X}^T\mathbf{Xa}-2\mathbf{X}^T\mathbf{y}+2\lambda n \mathbf{I}\mathbf{a}] = 0\\\\ 2\mathbf{X}^T\mathbf{Xa}-2\mathbf{X}^T\mathbf{y}+2\lambda n \mathbf{I} \mathbf{a} = 0\\\\ (\mathbf{X}^T\mathbf{X}+\lambda n \mathbf{I})\mathbf{a}-\mathbf{X}^T\mathbf{y} = 0\\\\ (\mathbf{X}^T\mathbf{X}+\lambda n \mathbf{I})\mathbf{a}=\mathbf{X}^T\mathbf{y}\\\\ \mathbf{a}=(\mathbf{X}^T\mathbf{X}+\lambda n \mathbf{I})^{-1}\mathbf{X}^T\mathbf{y}](https://s0.wp.com/latex.php?latex=J%28%5Cmathbf%7Ba%7D%29%3D%5Cfrac%7B1%7D%7B2m%7D%5B%28%5Cmathbf%7BXa%7D%29%5ET%5Cmathbf%7BXa%7D-2%28%5Cmathbf%7BXa%7D%29%5ET%5Cmathbf%7By%7D%2B%5Cmathbf%7By%7D%5ET%5Cmathbf%7By%7D%2B%5Clambda+n+%5Cmathbf%7BI%7D+%5Cmathbf%7Ba%7D%5ET%5Cmathbf%7Ba%7D%5D+%5C%5C%5C%5C++%5Cfrac%7BdJ%28%5Cmathbf%7Ba%7D%29%7D%7Bd%5Cmathbf%7Ba%7D%7D%3D%5Cfrac%7B1%7D%7B2m%7D%5B2%5Cmathbf%7BX%7D%5ET%5Cmathbf%7BXa%7D-2%5Cmathbf%7BX%7D%5ET%5Cmathbf%7By%7D%2B2%5Clambda+n+%5Cmathbf%7BI%7D%5Cmathbf%7Ba%7D%5D+%3D+0%5C%5C%5C%5C++2%5Cmathbf%7BX%7D%5ET%5Cmathbf%7BXa%7D-2%5Cmathbf%7BX%7D%5ET%5Cmathbf%7By%7D%2B2%5Clambda+n+%5Cmathbf%7BI%7D+%5Cmathbf%7Ba%7D+%3D+0%5C%5C%5C%5C++%28%5Cmathbf%7BX%7D%5ET%5Cmathbf%7BX%7D%2B%5Clambda+n+%5Cmathbf%7BI%7D%29%5Cmathbf%7Ba%7D-%5Cmathbf%7BX%7D%5ET%5Cmathbf%7By%7D+%3D+0%5C%5C%5C%5C++%28%5Cmathbf%7BX%7D%5ET%5Cmathbf%7BX%7D%2B%5Clambda+n+%5Cmathbf%7BI%7D%29%5Cmathbf%7Ba%7D%3D%5Cmathbf%7BX%7D%5ET%5Cmathbf%7By%7D%5C%5C%5C%5C++%5Cmathbf%7Ba%7D%3D%28%5Cmathbf%7BX%7D%5ET%5Cmathbf%7BX%7D%2B%5Clambda+n+%5Cmathbf%7BI%7D%29%5E%7B-1%7D%5Cmathbf%7BX%7D%5ET%5Cmathbf%7By%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Because 

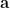
Hooray! We already get our parameter
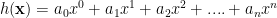
with 


Very well explained, Can you share me the code?
Hi,
Find the code here: https://github.com/ardianumam/Data-Mining-and-Big-Data-Analytics-Book/blob/master/13.4%20Regresi%20dg%20regularisasi.py
Sorry if the code (function name, comments) is written in Bahasa (Indonesian language).