We already discuss about how to estimate linear regression function using least square estimation here. But, many real problem cannot be modeled using only linear model. See picture here.

We cannot fit a line (green line) for those data points (blue dot), otherwise, it will give us a big error. For this case, we need polynomial function to fit those data (red line). We can write our hypothesis/prediction function using polynomial model as follows.
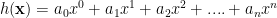
Equation above is general form of our hypothesis function with polynomial order 


Actually, the rest process is very similar with what we already discuss in linear regression here. The difference is only in the “design matrix” of 




We can write in another form for 


In this case, our design matrix is 
Then, we will make cost function to define our error function. We will use average of square error as our basic form. And our purpose is to minimize the error “as small as we can” (see trade-off topic in the bottom of this post). That’s why we name this with “least square estimation“. We can write our cost function as follows.

By plugging our 

Then we do some linear algebra to simplify that, we get:



Look carefully to the equation above, each term above will produce scalar value, for example :

Thus, we can change third term, 
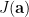

Once again, our purpose is to find a polynomial function that minimizes error, 
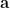




Voila! We can get the value of 

where design matrix

Again, see! The process is really similar with what we already discuss in linear regression here. The difference is only the design matrix.
Discussing order number trade-off (capability vs overfitting)
Using higher order, we can have more capability to fit more complex data points. See picture below for example.

From picture above, it is clearly see that the green line with 9 order polynomial function better on fitting the data points compare to those with lower order. But, higher order our model, it will be more prone to be overfitting. Overfitting means that our model is really good for data training in the term of giving really small error value, but it will gave us bigger error in prediction of unseen data. See here for the illustration.
 Picture above, red line uses higher order than green line, so that it gives smaller error in the training data compared to the green line’s. But, see when the input
Picture above, red line uses higher order than green line, so that it gives smaller error in the training data compared to the green line’s. But, see when the input 
To avoid overfitting problem, there is a technique called regularization. You can read further here.

thank you for your explanation