We already know that classification problem is predicting given input data into certain class. The simplest and most naive method is nearest neighbor. Given data training with class label, nearest neighbor classifier will assign given input data to the nearest data label. It can be done by using euclidean distance. Here is the illustration.
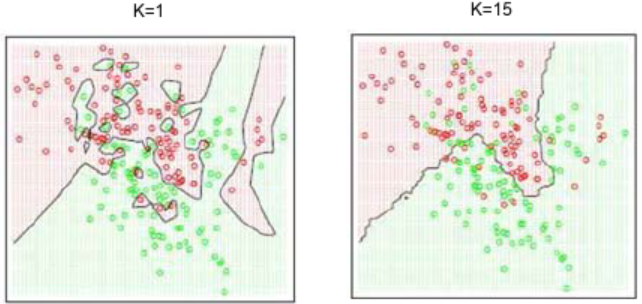
See picture above in the left, decision boundary is the black line. We can just simply assign class of given data input to the nearest data training class. We can extend using more than 1 nearest neighbors, that’s why we call it k-nearest neighbors, because we can specify the number of 

The characteristic of k-NN, when we have bigger number of
