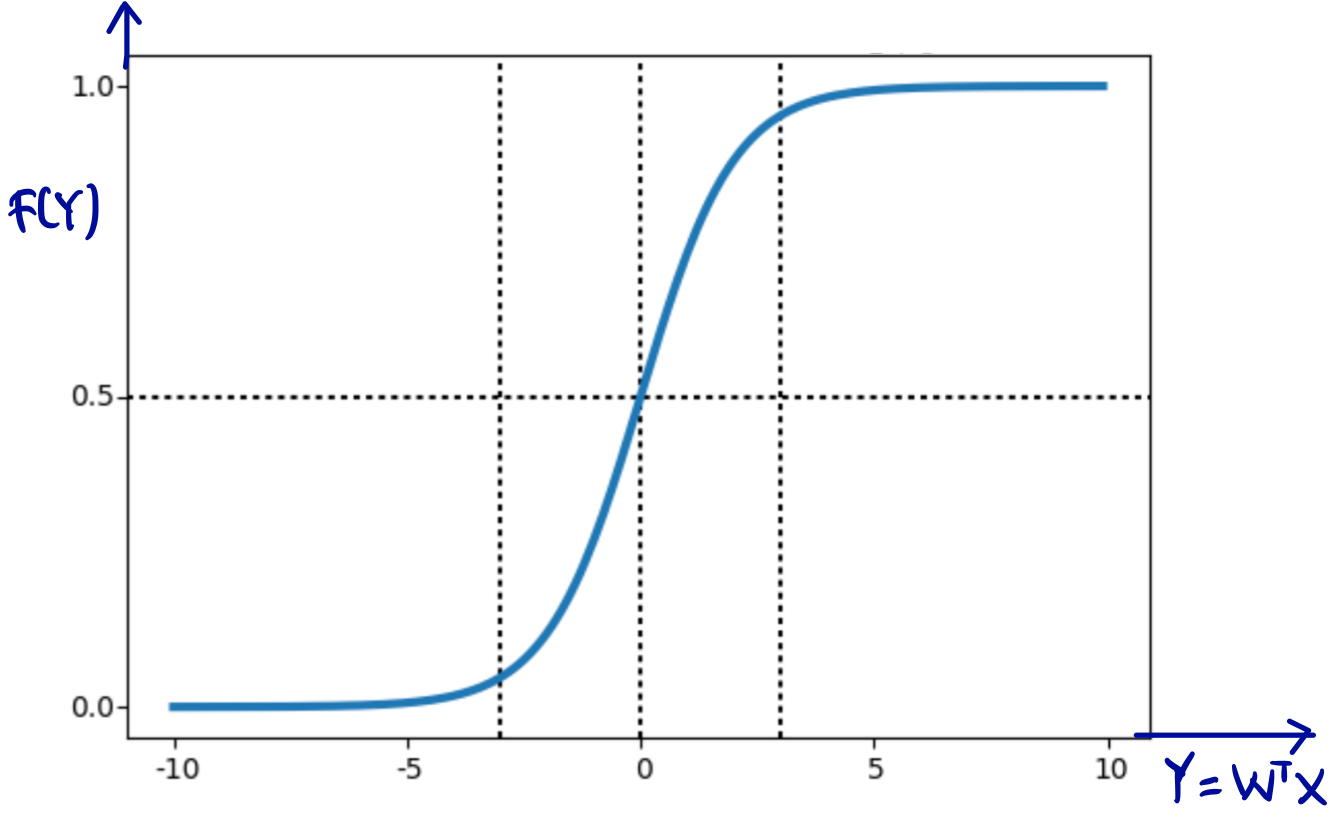
Logistic regression is an extension of regression method for classification. In the beginning of this machine learning series post, we already talked about regression using LSE here. To use regression approach for classification,we will feed the output regression  into so-called activation function, usually using sigmoid acivation function. See piture below.
into so-called activation function, usually using sigmoid acivation function. See piture below.
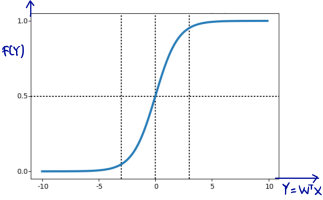
Sigmoid function will have output with s-shape like picture above whose output range is from zero to one. For classification, logistic regression is originally intended for binary classification. Regarding picture above, our output regression is fed sigmoid activation function. We will classify input to 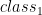 when the output is closed to 1 (formally when
when the output is closed to 1 (formally when 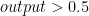 ) and classify to $class_2$ when the output is closed to 0 (formally when
) and classify to $class_2$ when the output is closed to 0 (formally when 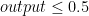 ) To do that, we can achieve by maximizing out likelihood using MLE (Maximum Likelihood Estiamtion).
) To do that, we can achieve by maximizing out likelihood using MLE (Maximum Likelihood Estiamtion).
We know that the output of our activation function  is ranging from 0 to 1, and we also know that linear regression is originally intended for binary classification (two outcomes). Therefore, we can model our likelihood using product of Bernoulli distribution. If you are not really familiar with Bernoulli distribution, we already talked here and you can take a look of it. Given m-pair data training
is ranging from 0 to 1, and we also know that linear regression is originally intended for binary classification (two outcomes). Therefore, we can model our likelihood using product of Bernoulli distribution. If you are not really familiar with Bernoulli distribution, we already talked here and you can take a look of it. Given m-pair data training  ,
,  here can be a vector such as
here can be a vector such as  . We can think that our each data , we have
. We can think that our each data , we have  . And for
. And for 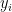 , it is only
, it is only  or
or  (binary class). Thus, our likelihood is product of Bernoulli distribution defined as follows.
(binary class). Thus, our likelihood is product of Bernoulli distribution defined as follows.

To find  that maximizes likelihood, we can take the first differential of our likelihood w.r.t , and make it equals to zero. As usual, to make it easier, we bring our likelihood to log form shown in the last line equation above.
that maximizes likelihood, we can take the first differential of our likelihood w.r.t , and make it equals to zero. As usual, to make it easier, we bring our likelihood to log form shown in the last line equation above.
![MLE = \underset{\textbf{W}}{argmax}\, [log\, likelihood]\\\\ \frac{\delta [log\,likelihood]}{\delta\textbf{W}}=\frac{\delta[\sum_{i=1}^{m}Y_i \, ln(\frac{1}{1+e^{-\boldsymbol{W^T}x_i}})+(1-Y_i)ln(\frac{e^{-\boldsymbol{W^Tx_i}}}{1+e^{-\boldsymbol{W^Tx_i}}})]}{\delta\textbf{W}}=0\\\\ \sum_{i=1}^{m}Y_i\frac{\delta[\, ln(\frac{1}{1+e^{-\boldsymbol{W^T}x_i}})]}{\delta\textbf{W}}+(1-Y_i)\frac{\delta\, [ln(\frac{e^{-\boldsymbol{W^Tx_i}}}{1+e^{-\boldsymbol{W^Tx_i}}})]}{\delta\textbf{W}}=0\\\\ \sum_{i=1}^{m}Y_i\frac{\delta[\, ln(1+e^{-\boldsymbol{W^T}x_i})^{-1}]}{\delta\textbf{W}}+(1-Y_i)\frac{\delta\, [ln(e^{-\boldsymbol{W^Tx_i}})-ln(1+e^{-\boldsymbol{W^Tx_i}})]}{\delta\textbf{W}}=0\\\\ \sum_{i=1}^{m}-Y_i\frac{\delta[\, ln(1+e^{-\boldsymbol{W^T}x_i})]}{\delta\textbf{W}}+(1-Y_i)\frac{\delta\, [ln(e^{-\boldsymbol{W^Tx_i}})-ln(1+e^{-\boldsymbol{W^Tx_i}})}{\delta\textbf{W}}=0\\\\ \sum_{i=1}^{m}-Y_i(\frac{1}{1+e^{-\boldsymbol{W^Tx_i}}}e^{-\boldsymbol{W^Tx_i}}.(-\boldsymbol{x_i}))\\+(1-Y_i)(-\boldsymbol{x_i}-(\frac{1}{1+e^{-\boldsymbol{W^Tx_i}}}e^{-\boldsymbol{W^Tx_i}}.(-\boldsymbol{x_i})))=0](https://s0.wp.com/latex.php?latex=MLE+%3D+%5Cunderset%7B%5Ctextbf%7BW%7D%7D%7Bargmax%7D%5C%2C+%5Blog%5C%2C+likelihood%5D%5C%5C%5C%5C++%5Cfrac%7B%5Cdelta+%5Blog%5C%2Clikelihood%5D%7D%7B%5Cdelta%5Ctextbf%7BW%7D%7D%3D%5Cfrac%7B%5Cdelta%5B%5Csum_%7Bi%3D1%7D%5E%7Bm%7DY_i+%5C%2C+ln%28%5Cfrac%7B1%7D%7B1%2Be%5E%7B-%5Cboldsymbol%7BW%5ET%7Dx_i%7D%7D%29%2B%281-Y_i%29ln%28%5Cfrac%7Be%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%7D%7B1%2Be%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%7D%29%5D%7D%7B%5Cdelta%5Ctextbf%7BW%7D%7D%3D0%5C%5C%5C%5C++%5Csum_%7Bi%3D1%7D%5E%7Bm%7DY_i%5Cfrac%7B%5Cdelta%5B%5C%2C+ln%28%5Cfrac%7B1%7D%7B1%2Be%5E%7B-%5Cboldsymbol%7BW%5ET%7Dx_i%7D%7D%29%5D%7D%7B%5Cdelta%5Ctextbf%7BW%7D%7D%2B%281-Y_i%29%5Cfrac%7B%5Cdelta%5C%2C+%5Bln%28%5Cfrac%7Be%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%7D%7B1%2Be%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%7D%29%5D%7D%7B%5Cdelta%5Ctextbf%7BW%7D%7D%3D0%5C%5C%5C%5C++%5Csum_%7Bi%3D1%7D%5E%7Bm%7DY_i%5Cfrac%7B%5Cdelta%5B%5C%2C+ln%281%2Be%5E%7B-%5Cboldsymbol%7BW%5ET%7Dx_i%7D%29%5E%7B-1%7D%5D%7D%7B%5Cdelta%5Ctextbf%7BW%7D%7D%2B%281-Y_i%29%5Cfrac%7B%5Cdelta%5C%2C+%5Bln%28e%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%29-ln%281%2Be%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%29%5D%7D%7B%5Cdelta%5Ctextbf%7BW%7D%7D%3D0%5C%5C%5C%5C++%5Csum_%7Bi%3D1%7D%5E%7Bm%7D-Y_i%5Cfrac%7B%5Cdelta%5B%5C%2C+ln%281%2Be%5E%7B-%5Cboldsymbol%7BW%5ET%7Dx_i%7D%29%5D%7D%7B%5Cdelta%5Ctextbf%7BW%7D%7D%2B%281-Y_i%29%5Cfrac%7B%5Cdelta%5C%2C+%5Bln%28e%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%29-ln%281%2Be%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%29%7D%7B%5Cdelta%5Ctextbf%7BW%7D%7D%3D0%5C%5C%5C%5C++%5Csum_%7Bi%3D1%7D%5E%7Bm%7D-Y_i%28%5Cfrac%7B1%7D%7B1%2Be%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%7De%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D.%28-%5Cboldsymbol%7Bx_i%7D%29%29%5C%5C%2B%281-Y_i%29%28-%5Cboldsymbol%7Bx_i%7D-%28%5Cfrac%7B1%7D%7B1%2Be%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%7De%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D.%28-%5Cboldsymbol%7Bx_i%7D%29%29%29%3D0&bg=ffffff&fg=000000&s=0&c=20201002)

Whoops! We are stuck here. We cannot find analytical function of that maximizes our likelihood, unlike what we did in LSE regression here that we could derive analytical form of that maximizes our loss function.
But, we have other methods to achieve this, maximizing our likelihood. We can use (1) gradient descent we already talk here, or (2) newton method for optimization we already talk here. Let’s break down for clearer understanding.
Using gradient descent to maximize likelihood in logistic regression
From our discussion here, we know that gradient descent formula is  . In our logistic regression above, it will be.
. In our logistic regression above, it will be.
![x_{j+1}=x_j-\lambda \frac{df(x)}{dx}\\\\ \textbf{W}_{j+1}=\textbf{W}_j-\lambda \frac{d[likelihood]}{d\textbf{W}}\\\\ \boxed{\textbf{W}_{j+1}=\textbf{W}_j-\lambda \sum_{i=1}^{m}\boldsymbol{x_i}(\frac{1}{1+e^{-\boldsymbol{W_n^Tx_i}}}-Y_i)}](https://s0.wp.com/latex.php?latex=x_%7Bj%2B1%7D%3Dx_j-%5Clambda+%5Cfrac%7Bdf%28x%29%7D%7Bdx%7D%5C%5C%5C%5C++%5Ctextbf%7BW%7D_%7Bj%2B1%7D%3D%5Ctextbf%7BW%7D_j-%5Clambda+%5Cfrac%7Bd%5Blikelihood%5D%7D%7Bd%5Ctextbf%7BW%7D%7D%5C%5C%5C%5C++%5Cboxed%7B%5Ctextbf%7BW%7D_%7Bj%2B1%7D%3D%5Ctextbf%7BW%7D_j-%5Clambda+%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%5Cboldsymbol%7Bx_i%7D%28%5Cfrac%7B1%7D%7B1%2Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%7D-Y_i%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
We get the last line above since we already derive the first differential of our likelihood w.r.t . Given m-pair data training  and n-order polynomial basis, we can write in matrix notation as follows.
and n-order polynomial basis, we can write in matrix notation as follows.

where 
 .
.
And finally we can just this formula to train our logistic regression iteratively. In every iteration, we will try to maximize the likelihood until we get converged for our  .
.
Using newton method to maximize likelihood in logistic regression
From our discussion about newton method for optimization here, we know that the formula is  . It is for scalar form of
. It is for scalar form of 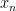 . When
. When  is a matrix, we can write
is a matrix, we can write  , where
, where  is hessian matrix, that basically is second derivative of
is hessian matrix, that basically is second derivative of  .
.
Using our newton method for formula above for optimization, we will try to derive the final formula for iteration update in our logistic regression case. Here we go.
![\boldsymbol{W}_{n+1}=\boldsymbol{W}_n-(H)^{-1}f'(x_n)\\\\ \boldsymbol{W}_{n+1}=\boldsymbol{W}_n-(\frac{\delta[\sum_{i=1}^{m}\boldsymbol{x_i}(\frac{1}{1+e^{-\boldsymbol{W_n^Tx_i}}}-Y_i)]}{\delta \textbf{W}})^{-1}f'(x_n)\\\\ \boldsymbol{W}_{n+1}=\boldsymbol{W}_n-((\frac{\delta[\sum_{i=1}^{m}(\frac{\boldsymbol{x_i}}{1+e^{-\boldsymbol{W_n^Tx_i}}})]}{\delta \textbf{W}}-\frac{\delta \boldsymbol{x_i}Y_i}{\delta \textbf{W}}))^{-1} f'(x_n)\\\\ \boldsymbol{W}_{n+1}=\boldsymbol{W}_n-((\frac{\delta[\sum_{i=1}^{m}(\frac{\boldsymbol{x_i}}{1+e^{-\boldsymbol{W_n^Tx_i}}})]}{\delta \textbf{W}}-0))^{-1} f'(x_n)\\\\ \boldsymbol{W}_{n+1}=\boldsymbol{W}_n-((\frac{\delta[\sum_{i=1}^{m}\boldsymbol{x_i}(1+e^{-\boldsymbol{W_n^Tx_i}})^{-1}]}{\delta \textbf{W}}))^{-1} f'(x_n)](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7BW%7D_%7Bn%2B1%7D%3D%5Cboldsymbol%7BW%7D_n-%28H%29%5E%7B-1%7Df%27%28x_n%29%5C%5C%5C%5C++%5Cboldsymbol%7BW%7D_%7Bn%2B1%7D%3D%5Cboldsymbol%7BW%7D_n-%28%5Cfrac%7B%5Cdelta%5B%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%5Cboldsymbol%7Bx_i%7D%28%5Cfrac%7B1%7D%7B1%2Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%7D-Y_i%29%5D%7D%7B%5Cdelta+%5Ctextbf%7BW%7D%7D%29%5E%7B-1%7Df%27%28x_n%29%5C%5C%5C%5C++%5Cboldsymbol%7BW%7D_%7Bn%2B1%7D%3D%5Cboldsymbol%7BW%7D_n-%28%28%5Cfrac%7B%5Cdelta%5B%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%28%5Cfrac%7B%5Cboldsymbol%7Bx_i%7D%7D%7B1%2Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%7D%29%5D%7D%7B%5Cdelta+%5Ctextbf%7BW%7D%7D-%5Cfrac%7B%5Cdelta+%5Cboldsymbol%7Bx_i%7DY_i%7D%7B%5Cdelta+%5Ctextbf%7BW%7D%7D%29%29%5E%7B-1%7D+f%27%28x_n%29%5C%5C%5C%5C++%5Cboldsymbol%7BW%7D_%7Bn%2B1%7D%3D%5Cboldsymbol%7BW%7D_n-%28%28%5Cfrac%7B%5Cdelta%5B%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%28%5Cfrac%7B%5Cboldsymbol%7Bx_i%7D%7D%7B1%2Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%7D%29%5D%7D%7B%5Cdelta+%5Ctextbf%7BW%7D%7D-0%29%29%5E%7B-1%7D+f%27%28x_n%29%5C%5C%5C%5C++%5Cboldsymbol%7BW%7D_%7Bn%2B1%7D%3D%5Cboldsymbol%7BW%7D_n-%28%28%5Cfrac%7B%5Cdelta%5B%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%5Cboldsymbol%7Bx_i%7D%281%2Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%29%5E%7B-1%7D%5D%7D%7B%5Cdelta+%5Ctextbf%7BW%7D%7D%29%29%5E%7B-1%7D+f%27%28x_n%29&bg=ffffff&fg=000000&s=0&c=20201002)
To solve the differential term ![\frac{\delta[(1+e^{-\boldsymbol{W_n^Tx_i}})^{-1}]}{\delta \textbf{W}}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cdelta%5B%281%2Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%29%5E%7B-1%7D%5D%7D%7B%5Cdelta+%5Ctextbf%7BW%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , we can use chain rule in differentiation. Let
, we can use chain rule in differentiation. Let  , and
, and  .
.
![\frac{\delta[(1+e^{-\boldsymbol{W_n^Tx_i}})^{-1}]}{\delta \textbf{W}}=\frac{\delta u^{-1}}{\delta u}\frac{\delta u}{\delta v}\frac{\delta v}{\delta \textbf{W}}\\\\ \frac{\delta[(1+e^{-\boldsymbol{W_n^Tx_i}})^{-1}]}{\delta \textbf{W}}=-u^{-2}\frac{\delta [1+e^{-\boldsymbol{W^Tx_i}}]}{\delta [\boldsymbol{W^Tx_i}]}\frac{\delta [\boldsymbol{W^Tx_i}]}{\delta \textbf{W}}\\\\ \frac{\delta[(1+e^{-\boldsymbol{W_n^Tx_i}})^{-1}]}{\delta \textbf{W}}=-u^{-2}(-1)(e^{-\boldsymbol{W_n^Tx_i}})\boldsymbol{x}_i\\\\ \frac{\delta[(1+e^{-\boldsymbol{W_n^Tx_i}})^{-1}]}{\delta \textbf{W}}=\frac{e^{-\boldsymbol{W_n^Tx_i}}}{(1+e^{-\boldsymbol{W^Tx_i}})^2}\boldsymbol{x}_i](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cdelta%5B%281%2Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%29%5E%7B-1%7D%5D%7D%7B%5Cdelta+%5Ctextbf%7BW%7D%7D%3D%5Cfrac%7B%5Cdelta+u%5E%7B-1%7D%7D%7B%5Cdelta+u%7D%5Cfrac%7B%5Cdelta+u%7D%7B%5Cdelta+v%7D%5Cfrac%7B%5Cdelta+v%7D%7B%5Cdelta+%5Ctextbf%7BW%7D%7D%5C%5C%5C%5C++%5Cfrac%7B%5Cdelta%5B%281%2Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%29%5E%7B-1%7D%5D%7D%7B%5Cdelta+%5Ctextbf%7BW%7D%7D%3D-u%5E%7B-2%7D%5Cfrac%7B%5Cdelta+%5B1%2Be%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%5D%7D%7B%5Cdelta+%5B%5Cboldsymbol%7BW%5ETx_i%7D%5D%7D%5Cfrac%7B%5Cdelta+%5B%5Cboldsymbol%7BW%5ETx_i%7D%5D%7D%7B%5Cdelta+%5Ctextbf%7BW%7D%7D%5C%5C%5C%5C++%5Cfrac%7B%5Cdelta%5B%281%2Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%29%5E%7B-1%7D%5D%7D%7B%5Cdelta+%5Ctextbf%7BW%7D%7D%3D-u%5E%7B-2%7D%28-1%29%28e%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%29%5Cboldsymbol%7Bx%7D_i%5C%5C%5C%5C++%5Cfrac%7B%5Cdelta%5B%281%2Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%29%5E%7B-1%7D%5D%7D%7B%5Cdelta+%5Ctextbf%7BW%7D%7D%3D%5Cfrac%7Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%7D%7B%281%2Be%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%29%5E2%7D%5Cboldsymbol%7Bx%7D_i&bg=ffffff&fg=000000&s=0&c=20201002)
Plugging back our result, we get.
![\boldsymbol{W}_{n+1}=\boldsymbol{W}_n-((\frac{\delta[\sum_{i=1}^{m}\boldsymbol{x_i}(1+e^{-\boldsymbol{W_n^Tx_i}})^{-1}]}{\delta \textbf{W}}))^{-1} f'(x_n)\\\\ \boldsymbol{W}_{n+1}=\boldsymbol{W}_n-(\sum_{i=1}^{m}[\boldsymbol{x_i}\frac{e^{-\boldsymbol{W_n^Tx_i}}}{(1+e^{-\boldsymbol{W^Tx_i}})^2}\boldsymbol{x}_i])^{-1} f'(x_n)\\\\ \boldsymbol{W}_{n+1}=\boldsymbol{W}_n-(\sum_{i=1}^{m}[\boldsymbol{x_i}\frac{e^{-\boldsymbol{W_n^Tx_i}}}{(1+e^{-\boldsymbol{W^Tx_i}})^2}\boldsymbol{x}_i^T])^{-1} f'(x_n)](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7BW%7D_%7Bn%2B1%7D%3D%5Cboldsymbol%7BW%7D_n-%28%28%5Cfrac%7B%5Cdelta%5B%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%5Cboldsymbol%7Bx_i%7D%281%2Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%29%5E%7B-1%7D%5D%7D%7B%5Cdelta+%5Ctextbf%7BW%7D%7D%29%29%5E%7B-1%7D+f%27%28x_n%29%5C%5C%5C%5C++%5Cboldsymbol%7BW%7D_%7Bn%2B1%7D%3D%5Cboldsymbol%7BW%7D_n-%28%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%5B%5Cboldsymbol%7Bx_i%7D%5Cfrac%7Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%7D%7B%281%2Be%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%29%5E2%7D%5Cboldsymbol%7Bx%7D_i%5D%29%5E%7B-1%7D+f%27%28x_n%29%5C%5C%5C%5C++%5Cboldsymbol%7BW%7D_%7Bn%2B1%7D%3D%5Cboldsymbol%7BW%7D_n-%28%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%5B%5Cboldsymbol%7Bx_i%7D%5Cfrac%7Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%7D%7B%281%2Be%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%29%5E2%7D%5Cboldsymbol%7Bx%7D_i%5ET%5D%29%5E%7B-1%7D+f%27%28x_n%29&bg=ffffff&fg=000000&s=0&c=20201002)
We need to take transpose of  in the last line of equation above since it’s square of vector. And we take the later of to be transposed because we know that this term should produce
in the last line of equation above since it’s square of vector. And we take the later of to be transposed because we know that this term should produce 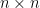 matrix. Just like what we did in the gradient descent, we can write the matrix form of it and substitute
matrix. Just like what we did in the gradient descent, we can write the matrix form of it and substitute  , we get.
, we get.
![\boldsymbol{W}_{n+1}=\boldsymbol{W}_n-(\sum_{i=1}^{m}[\boldsymbol{x_i}\frac{e^{-\boldsymbol{W_n^Tx_i}}}{(1+e^{-\boldsymbol{W^Tx_i}})^2}\boldsymbol{x}_i^T])^{-1} f'(x_n)\\\\ \boxed{\boldsymbol{W}_{n+1}=\boldsymbol{W}_n-(\boldsymbol{X}^T\boldsymbol{R}\boldsymbol{X})^{-1}\boldsymbol{X}^T(\boldsymbol{f(W_n^Tx)}-\textbf{Y})}](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7BW%7D_%7Bn%2B1%7D%3D%5Cboldsymbol%7BW%7D_n-%28%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%5B%5Cboldsymbol%7Bx_i%7D%5Cfrac%7Be%5E%7B-%5Cboldsymbol%7BW_n%5ETx_i%7D%7D%7D%7B%281%2Be%5E%7B-%5Cboldsymbol%7BW%5ETx_i%7D%7D%29%5E2%7D%5Cboldsymbol%7Bx%7D_i%5ET%5D%29%5E%7B-1%7D+f%27%28x_n%29%5C%5C%5C%5C++%5Cboxed%7B%5Cboldsymbol%7BW%7D_%7Bn%2B1%7D%3D%5Cboldsymbol%7BW%7D_n-%28%5Cboldsymbol%7BX%7D%5ET%5Cboldsymbol%7BR%7D%5Cboldsymbol%7BX%7D%29%5E%7B-1%7D%5Cboldsymbol%7BX%7D%5ET%28%5Cboldsymbol%7Bf%28W_n%5ETx%29%7D-%5Ctextbf%7BY%7D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
where  is diagonal matrix
is diagonal matrix  x of
x of  . We prefer use
. We prefer use  because it is away more numerically stable when implementing into code in our computer. Then, we can just use this formula to train our logistic regression iteratively. Note that since this method needs inversing of our Hessian matrix, sometimes we find that our Hessian matrix is singular/not invertible.
because it is away more numerically stable when implementing into code in our computer. Then, we can just use this formula to train our logistic regression iteratively. Note that since this method needs inversing of our Hessian matrix, sometimes we find that our Hessian matrix is singular/not invertible.

Hi why do you flip it? When you find the MLE why multiply it by -1?