Background
To get strong understanding about EM concept, digging from the mathematical derivation is good way for it. But before it, let’s put the condition first. EM method is intended for clustering, and the most familiar method is k-means clustering, which is the special case of EM method that use Gaussian mixture to model the cluster areas and using hard clustering instead of soft clustering.
See picture below.
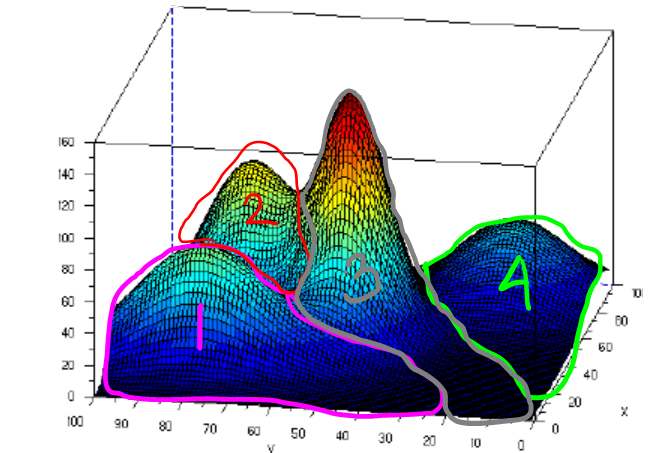
Picture above shows that we have 4 clusters where each cluster is modeled using Gaussian. To determine the data belongs to which cluster, we can just determine by finding the maximal value among the fourth Gaussian value. The data will be clustered to the cluster whose Gaussian value is maximal in that location. For instance, the area in the pink line boundary has maximal Gaussian value which is from Gaussian value in cluster 1, likewise for other clusters. Doing this type of clustering, the clustering boundary may intersects each others and taking cluster whose the value is maximal, is called soft clustering. Whereas for hard clustering, the boundary doesn’t intersect each others. To be able to cluster like that, we need parameters mean and variance of all those 4 Gaussian distributions, given data set input without class label. And we can achieve this by using EM method.
Ok, we already get the basic idea how it works. Next, we will dig through the mathematical approach. To do this, we choose a case which its distribution is Bernoulli distribution so that it will be much easier to derive. If in Gaussian we need parameter mean and variance, in Bernoulli distribution, we need parameter 


Given two tossing coins 


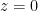
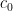
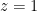


After we get all setups, we will try to do MLE (Maximum Likelihood Estimation). We can construct our likelihood as Bernoulli probability as follows.

Likelihood formula above is really straightforward. If you find it difficult to understand, you may check Bernoulli distribution we already talk here. Next, we will do MLE by maximizing the likelihood to find parameter 

![likelihood=\sum_{i=1}^{n}[(1-z_i)ln(\lambda P_{c_0}^{x_i}(1-P_{c_0}^{x_i})^{1-x_i})+z_iln(1-\lambda)P_{c_1}^{x_i}(1-P_{c_1})^{1-x_i}]\\\\ likelihood=\sum_{i=1}^{n}[(1-z_i)ln\lambda +(1-z_i)x_ilnP_{c_0}+(1-z_i)(1-x_i)ln(1-P_{c_0})\\ \hspace*{60pt} +z_iln(1-\lambda) +z_ix_ilnP_{c_1}+z_i(1-x_i)ln(1-P_{c_1})]](https://s0.wp.com/latex.php?latex=likelihood%3D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5B%281-z_i%29ln%28%5Clambda+P_%7Bc_0%7D%5E%7Bx_i%7D%281-P_%7Bc_0%7D%5E%7Bx_i%7D%29%5E%7B1-x_i%7D%29%2Bz_iln%281-%5Clambda%29P_%7Bc_1%7D%5E%7Bx_i%7D%281-P_%7Bc_1%7D%29%5E%7B1-x_i%7D%5D%5C%5C%5C%5C++likelihood%3D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5B%281-z_i%29ln%5Clambda+%2B%281-z_i%29x_ilnP_%7Bc_0%7D%2B%281-z_i%29%281-x_i%29ln%281-P_%7Bc_0%7D%29%5C%5C++%5Chspace%2A%7B60pt%7D+%2Bz_iln%281-%5Clambda%29+%2Bz_ix_ilnP_%7Bc_1%7D%2Bz_i%281-x_i%29ln%281-P_%7Bc_1%7D%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
To find
![\frac{\delta [likelihood]}{\delta \lambda}=\frac{\delta[\sum_{i=1}^{n}(1-z_i)ln \lambda + z_i ln(1-\lambda)]}{\delta \lambda}=0](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cdelta+%5Blikelihood%5D%7D%7B%5Cdelta+%5Clambda%7D%3D%5Cfrac%7B%5Cdelta%5B%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%281-z_i%29ln+%5Clambda+%2B+z_i+ln%281-%5Clambda%29%5D%7D%7B%5Cdelta+%5Clambda%7D%3D0&bg=ffffff&fg=000000&s=0&c=20201002)
We get formula above because the other terms don’t have
![\frac{\delta [likelihood]}{\delta \lambda}=\frac{\delta [ln \lambda\sum_{i=1}^{n}(1-z_i) + ln(1-\lambda) \sum_{i=1}^{n} z_i]}{\delta \lambda}=0\\\\ \frac{1}{\lambda}\sum_{i=1}^{n}(1-z_i)=\frac{1}{(1-\lambda)}\sum_{i=1}^{n}z_i\\\\ (1-\lambda)\sum_{i=1}^{n}(1-z_i)=\lambda \sum_{i=1}^{n} z_i\\\\ \sum_{i=1}^{n}(1-z_i)-\lambda\sum_{i=1}^{n}(1-z_i)=\lambda \sum_{i=1}^{n} z_i\\\\ \sum_{i=1}^{n}(1-z_i)-\lambda\sum_{i=1}^{n}(1-z_i)=\lambda \sum_{i=1}^{n} z_i+\lambda\sum_{i=1}^{n}(1-z_i)\\\\ \sum_{i=1}^{n}(1-z_i)=\lambda \sum_{i=1}^{n} [z_i+(1-z_i)]\\\\ \sum_{i=1}^{n}(1-z_i)=\lambda \sum_{i=1}^{n}1\\\\ \sum_{i=1}^{n}(1-z_i)=\lambda n\\\\ \boxed{\lambda=\frac{\sum_{i=1}^{n}(1-z_i)}{n}}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cdelta+%5Blikelihood%5D%7D%7B%5Cdelta+%5Clambda%7D%3D%5Cfrac%7B%5Cdelta+%5Bln+%5Clambda%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%281-z_i%29+%2B+ln%281-%5Clambda%29+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+z_i%5D%7D%7B%5Cdelta+%5Clambda%7D%3D0%5C%5C%5C%5C++%5Cfrac%7B1%7D%7B%5Clambda%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%281-z_i%29%3D%5Cfrac%7B1%7D%7B%281-%5Clambda%29%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7Dz_i%5C%5C%5C%5C++%281-%5Clambda%29%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%281-z_i%29%3D%5Clambda+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+z_i%5C%5C%5C%5C++%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%281-z_i%29-%5Clambda%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%281-z_i%29%3D%5Clambda+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+z_i%5C%5C%5C%5C++%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%281-z_i%29-%5Clambda%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%281-z_i%29%3D%5Clambda+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+z_i%2B%5Clambda%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%281-z_i%29%5C%5C%5C%5C++%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%281-z_i%29%3D%5Clambda+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%5Bz_i%2B%281-z_i%29%5D%5C%5C%5C%5C++%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%281-z_i%29%3D%5Clambda+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D1%5C%5C%5C%5C++%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%281-z_i%29%3D%5Clambda+n%5C%5C%5C%5C++%5Cboxed%7B%5Clambda%3D%5Cfrac%7B%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%281-z_i%29%7D%7Bn%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
As for other parameters 


Unlabeled data (no data z) → using EM method
What we did in the “background” discussion above is when we have class data label, which is denoted by

The first and second line formula are the joint probability of cluster 0 and cluster 1 respectively. Because we don’t have data label
![likelihood = \sum_{i=1}^{n} [w_{{c0}_i} ln \lambda P_{c_0}^{x_i}(1-P_{c_0})^{1-x_i}+(1-w_{{c0}_i})ln (1-\lambda) P_{c_1}^{x_i}(1-P_{c_1})^{1-x_i}]](https://s0.wp.com/latex.php?latex=likelihood+%3D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%5Bw_%7B%7Bc0%7D_i%7D+ln+%5Clambda+P_%7Bc_0%7D%5E%7Bx_i%7D%281-P_%7Bc_0%7D%29%5E%7B1-x_i%7D%2B%281-w_%7B%7Bc0%7D_i%7D%29ln+%281-%5Clambda%29+P_%7Bc_1%7D%5E%7Bx_i%7D%281-P_%7Bc_1%7D%29%5E%7B1-x_i%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Doing MLE that is similar what we did before in labelled data case, we will get the final result as follows.

And finally, our two clusters can be constructed by using parameters 
- Initiate our model parameters. In this case, we use Bernoulli to model our cluster areas, thus those parameters are mixing coefficient
- After that, we can calculate weighting value (responsibility), in our case would be
- After we get weighting value
- And then this process keep repeated iteratively by doing step (2) and (3) until it converged. We will get the final parameter values of our cluster area models. In our case will be parameters
and
Relation between EM method and k-means clustering
From discussion above, we already know that EM is constructed using mixture of distribution model, such as BMM (Bernoulli Mixture Model) and GMM (Gaussian Mixture Model). Like we already mention above, k-means clustering is just special case of EM method, which is using GMM and hard clustering. Instead of calculating and giving weight/responsibility value to each data for each clusters, we will set weight/responsibility value to 1 for data input belonging to cluster whose mean value is the nearest to that data input, and set zero weight value for other clusters. And the are just same. Here are the steps summary for doing k-Means clustering.
- Specify how many clusters, and initiate means for each clusters. Each cluster will have means that is same number with the given data input dimension.
- Assign each data input into each cluster. Each data input belongs to cluster whose the mean is the nearest one.
- After we do step (2), we will members in each clusters. Then, re-calculate the means of each there clusters.
- Iterate step (2) and (3) until it converged. Converged in k-means is when the means of each clusters don’t change again in the next iteration compared to the previous one.
In k-means, the are some considerations:
- We need to specify how many clusters we want to make, and we need to specify means of each clusters.
- Different means initialization may give different final result clusters
- It is possible that we will have zero member in certain cluster
- k-means lacks robustness to outliers. Because k-means will treat with same weight for normal data and outliers data. Whereas, for EM method, it will treat with different weight, so, it is more robust to outliers.
