Estimator is a statistic, usually in a function of the data, that is used to infer the value of an unknown parameter in a statistical model. During this post, we will talk about estimator for mean and variance of sampled data. We can determine a good estimator by calculating the bias of it. A good estimator should give bias closed to zero. Let 

![bias = E[\hat{\theta}]-\theta](https://s0.wp.com/latex.php?latex=bias+%3D+E%5B%5Chat%7B%5Ctheta%7D%5D-%5Ctheta&bg=ffffff&fg=000000&s=0&c=20201002)
We will use bias formula above to check whether our estimator is good or not. And during this post, we will check our estimator we already derived by MLE here, which are mean and variance. Let’s write them first.

where 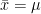
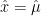
Let’s do 
![E[\hat{\mu}]=E[\frac{1}{n}\sum_{i=1}^{n}x_i]\\\\ E[\hat{\mu}]=\frac{1}{n}\sum_{i=1}^{n}E[x_i]\\\\ E[\hat{\mu}]=\frac{1}{n}\sum_{i=1}^{n}\bar{x}\\\\ E[\hat{\mu}]=\frac{1}{n}n\bar{x}\\\\ E[\hat{\mu}]=\bar{x}](https://s0.wp.com/latex.php?latex=E%5B%5Chat%7B%5Cmu%7D%5D%3DE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7Dx_i%5D%5C%5C%5C%5C+E%5B%5Chat%7B%5Cmu%7D%5D%3D%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7DE%5Bx_i%5D%5C%5C%5C%5C+E%5B%5Chat%7B%5Cmu%7D%5D%3D%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5Cbar%7Bx%7D%5C%5C%5C%5C+E%5B%5Chat%7B%5Cmu%7D%5D%3D%5Cfrac%7B1%7D%7Bn%7Dn%5Cbar%7Bx%7D%5C%5C%5C%5C+E%5B%5Chat%7B%5Cmu%7D%5D%3D%5Cbar%7Bx%7D&bg=ffffff&fg=000000&s=0&c=20201002)
For our estimator 
![bias = E[\hat{\mu}]-\mu=\bar{x}-\bar{x}=0](https://s0.wp.com/latex.php?latex=bias+%3D+E%5B%5Chat%7B%5Cmu%7D%5D-%5Cmu%3D%5Cbar%7Bx%7D-%5Cbar%7Bx%7D%3D0&bg=ffffff&fg=000000&s=0&c=20201002)


Let’s do for variance.
![E[\sigma^2_{MLE}]=E[\frac{1}{n}\sum_{i=1}^{n}(x_i-\hat{\mu})^2]\\\\ E[\sigma^2_{MLE}]=E[\frac{1}{n}\sum_{i=1}^{n}((x_i-\mu)-(\hat{\mu}-\mu))^2]](https://s0.wp.com/latex.php?latex=E%5B%5Csigma%5E2_%7BMLE%7D%5D%3DE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28x_i-%5Chat%7B%5Cmu%7D%29%5E2%5D%5C%5C%5C%5C+E%5B%5Csigma%5E2_%7BMLE%7D%5D%3DE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28%28x_i-%5Cmu%29-%28%5Chat%7B%5Cmu%7D-%5Cmu%29%29%5E2%5D&bg=ffffff&fg=000000&s=0&c=20201002)
To make it easy to derive, let 

![E[\hat{\sigma}^2]=E[\frac{1}{n}\sum_{i=1}^{n}(x_i-\hat{\mu})^2]\\\\ E[\hat{\sigma}^2]=E[\frac{1}{n}\sum_{i=1}^{n}((x_i-\mu)-(\hat{\mu}-\mu))^2]\\\\ E[\hat{\sigma}^2]=E[\frac{1}{n}\sum_{i=1}^{n}(a-b)^2]\\\\ E[\hat{\sigma}^2]=E[\frac{1}{n}\sum_{i=1}^{n}(a^2-2ab+b^2)]\\\\ E[\hat{\sigma}^2]=E[\frac{1}{n}\sum_{i=1}^{n}a^2]-E[\frac{2}{n}\sum_{i=1}^{n}(ab)]+E[\frac{1}{n}\sum_{i=1}^{n}(b^2)]\\\\ E[\hat{\sigma}^2]=E[\frac{1}{n}\sum_{i=1}^{n}a^2]-E[\frac{2}{n}b\sum_{i=1}^{n}(a)]+E[\frac{1}{n}n(b^2)]\,... \,(i)\\\\ E[\hat{\sigma}^2]=E[\frac{1}{n}\sum_{i=1}^{n}a^2]-E[\frac{2}{n}bnb]+E[b^2]\,... \,(ii)\\\\ E[\hat{\sigma}^2]=E[\frac{1}{n}\sum_{i=1}^{n}a^2]-2E[b^2]+E[b^2]\\\\ E[\hat{\sigma}^2]=E[\frac{1}{n}\sum_{i=1}^{n}a^2]-E[b^2]\\\\ E[\hat{\sigma}^2]=E[\frac{1}{n}\sum_{i=1}^{n}(x_i-\mu)^2]-E[(\hat{\mu}-\mu)^2]\\\\ E[\hat{\sigma}^2]=\sigma^2-E[(\hat{\mu}-E[\hat{\mu}])^2]\,... \,(iii)\\\\ E[\hat{\sigma}^2]=\sigma^2-\frac{\sigma^2}{n}\,... \,(iv)](https://s0.wp.com/latex.php?latex=E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3DE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28x_i-%5Chat%7B%5Cmu%7D%29%5E2%5D%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3DE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28%28x_i-%5Cmu%29-%28%5Chat%7B%5Cmu%7D-%5Cmu%29%29%5E2%5D%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3DE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28a-b%29%5E2%5D%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3DE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28a%5E2-2ab%2Bb%5E2%29%5D%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3DE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7Da%5E2%5D-E%5B%5Cfrac%7B2%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28ab%29%5D%2BE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28b%5E2%29%5D%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3DE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7Da%5E2%5D-E%5B%5Cfrac%7B2%7D%7Bn%7Db%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28a%29%5D%2BE%5B%5Cfrac%7B1%7D%7Bn%7Dn%28b%5E2%29%5D%5C%2C...+%5C%2C%28i%29%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3DE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7Da%5E2%5D-E%5B%5Cfrac%7B2%7D%7Bn%7Dbnb%5D%2BE%5Bb%5E2%5D%5C%2C...+%5C%2C%28ii%29%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3DE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7Da%5E2%5D-2E%5Bb%5E2%5D%2BE%5Bb%5E2%5D%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3DE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7Da%5E2%5D-E%5Bb%5E2%5D%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3DE%5B%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28x_i-%5Cmu%29%5E2%5D-E%5B%28%5Chat%7B%5Cmu%7D-%5Cmu%29%5E2%5D%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3D%5Csigma%5E2-E%5B%28%5Chat%7B%5Cmu%7D-E%5B%5Chat%7B%5Cmu%7D%5D%29%5E2%5D%5C%2C...+%5C%2C%28iii%29%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3D%5Csigma%5E2-%5Cfrac%7B%5Csigma%5E2%7D%7Bn%7D%5C%2C...+%5C%2C%28iv%29&bg=ffffff&fg=000000&s=0&c=20201002)
Let’s us clarify first how we can get 
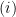





![E[\hat{\mu}]=\hat{x}=\mu](https://s0.wp.com/latex.php?latex=E%5B%5Chat%7B%5Cmu%7D%5D%3D%5Chat%7Bx%7D%3D%5Cmu&bg=ffffff&fg=000000&s=0&c=20201002)

![E[(\hat{\mu}-E[\hat{\mu}])^2]=var[\hat{\mu}]\\\\ var[\hat{\mu}]=var[\frac{\sum_{i=1}^{n}x_i}{n}]\\\\ var[\hat{\mu}]=\frac{1}{n^2}[var(x_1)+var(x_2)+... +var(x_n)]\\\\ var[\hat{\mu}]=\frac{1}{n^2} \,n\,\sigma^2\\\\ var[\hat{\mu}]=\frac{\sigma^2}{n}](https://s0.wp.com/latex.php?latex=E%5B%28%5Chat%7B%5Cmu%7D-E%5B%5Chat%7B%5Cmu%7D%5D%29%5E2%5D%3Dvar%5B%5Chat%7B%5Cmu%7D%5D%5C%5C%5C%5C+var%5B%5Chat%7B%5Cmu%7D%5D%3Dvar%5B%5Cfrac%7B%5Csum_%7Bi%3D1%7D%5E%7Bn%7Dx_i%7D%7Bn%7D%5D%5C%5C%5C%5C+var%5B%5Chat%7B%5Cmu%7D%5D%3D%5Cfrac%7B1%7D%7Bn%5E2%7D%5Bvar%28x_1%29%2Bvar%28x_2%29%2B...+%2Bvar%28x_n%29%5D%5C%5C%5C%5C+var%5B%5Chat%7B%5Cmu%7D%5D%3D%5Cfrac%7B1%7D%7Bn%5E2%7D+%5C%2Cn%5C%2C%5Csigma%5E2%5C%5C%5C%5C+var%5B%5Chat%7B%5Cmu%7D%5D%3D%5Cfrac%7B%5Csigma%5E2%7D%7Bn%7D&bg=ffffff&fg=000000&s=0&c=20201002)
And now let’s check the bias of this estimator.
![bias=E[\hat{\sigma}^2]-sigma^2=(\sigma^2-\frac{\sigma^2}{n}))-\sigma^2\\\\bias=-\frac{\sigma^2}{n}](https://s0.wp.com/latex.php?latex=bias%3DE%5B%5Chat%7B%5Csigma%7D%5E2%5D-sigma%5E2%3D%28%5Csigma%5E2-%5Cfrac%7B%5Csigma%5E2%7D%7Bn%7D%29%29-%5Csigma%5E2%5C%5C%5C%5Cbias%3D-%5Cfrac%7B%5Csigma%5E2%7D%7Bn%7D&bg=ffffff&fg=000000&s=0&c=20201002)
From equation above we see that variance we get from MLE does not give us zero bias. That’s why when we calculate variance of sampled data, we usually use this formula 
![E[\hat{\sigma}^2]=E[\frac{1}{(n-1)}\sum_{i=1}^{n}(x_i-\hat{\mu})](https://s0.wp.com/latex.php?latex=E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3DE%5B%5Cfrac%7B1%7D%7B%28n-1%29%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%28x_i-%5Chat%7B%5Cmu%7D%29&bg=ffffff&fg=000000&s=0&c=20201002)
Doing similar with what we already did before, we will get:
![E[\hat{\sigma}^2]=E[\frac{1}{(n-1)}\sum_{i=1}^{n}a]-E[\frac{n}{n-1}b^2]\\\\ E[\hat{\sigma}^2]=E[\frac{n}{(n-1)}\frac{1}{n}\sum_{i=1}^{n}a]-E[\frac{n}{n-1}b^2]\\\\ E[\hat{\sigma}^2]=\frac{n}{(n-1)}\sigma^2-\frac{n}{n-1}E[b^2]\\\\ E[\hat{\sigma}^2]=\frac{n}{(n-1)}\sigma^2-\frac{n}{n-1}\frac{\sigma^2}{n}\\\\ E[\hat{\sigma}^2]=\frac{n}{(n-1)}\sigma^2-\frac{1}{n-1}\sigma^2\\\\ E[\hat{\sigma}^2]=(\frac{n}{(n-1)}-\frac{1}{n-1})\sigma^2\\\\ E[\hat{\sigma}^2]=(\frac{n-1}{(n-1)})\sigma^2\\\\ E[\hat{\sigma}^2]=(1)\sigma^2\\\\ E[\hat{\sigma}^2]=\sigma^2](https://s0.wp.com/latex.php?latex=E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3DE%5B%5Cfrac%7B1%7D%7B%28n-1%29%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7Da%5D-E%5B%5Cfrac%7Bn%7D%7Bn-1%7Db%5E2%5D%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3DE%5B%5Cfrac%7Bn%7D%7B%28n-1%29%7D%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7Da%5D-E%5B%5Cfrac%7Bn%7D%7Bn-1%7Db%5E2%5D%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3D%5Cfrac%7Bn%7D%7B%28n-1%29%7D%5Csigma%5E2-%5Cfrac%7Bn%7D%7Bn-1%7DE%5Bb%5E2%5D%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3D%5Cfrac%7Bn%7D%7B%28n-1%29%7D%5Csigma%5E2-%5Cfrac%7Bn%7D%7Bn-1%7D%5Cfrac%7B%5Csigma%5E2%7D%7Bn%7D%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3D%5Cfrac%7Bn%7D%7B%28n-1%29%7D%5Csigma%5E2-%5Cfrac%7B1%7D%7Bn-1%7D%5Csigma%5E2%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3D%28%5Cfrac%7Bn%7D%7B%28n-1%29%7D-%5Cfrac%7B1%7D%7Bn-1%7D%29%5Csigma%5E2%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3D%28%5Cfrac%7Bn-1%7D%7B%28n-1%29%7D%29%5Csigma%5E2%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3D%281%29%5Csigma%5E2%5C%5C%5C%5C+E%5B%5Chat%7B%5Csigma%7D%5E2%5D%3D%5Csigma%5E2&bg=ffffff&fg=000000&s=0&c=20201002)
And now let’s check the bias of this estimator.
![bias=E[\hat{\sigma}^2]-sigma^2=\sigma^2-\sigma^2\\\\bias=0](https://s0.wp.com/latex.php?latex=bias%3DE%5B%5Chat%7B%5Csigma%7D%5E2%5D-sigma%5E2%3D%5Csigma%5E2-%5Csigma%5E2%5C%5C%5C%5Cbias%3D0&bg=ffffff&fg=000000&s=0&c=20201002)
Voila! We can successfully derive that by using 
